H16
- 3/3/2025 - Comme l’annonce Emmanuel Macron en fanfaronnant depuis son compte X, la formidable dynamique du Sommet de l’IA à Paris se poursuit, alors bon, c’est décidé, fini de rire, et en avant ! La France, fermement cornaquée par son extraordinaire président, se lance à l’assaut de l’Intelligence Artificielle et entraînera avec elle toute l’Europe dans une conquête triomphale de l’avenir de l’Humanité. Envoyez la musique !

Cependant, avant cette consécration, il faudra probablement régler quelques petits soucis, car pendant que ça cabotine joyeusement du côté de l’Élysée, les services administratifs de l’État continuent d’empiler les échecs informatiques avec une constance troublante : dans une presse particulièrement discrète, on apprend ainsi que le projet informatique Scribe, ce logiciel de rédaction de procédures pénales destinés à la police et la magistrature françaises, vient d’être abandonné après neuf longues années de merdoiements intenses.
Son histoire mérite d’être contée, tant elle se rapproche des précédentes foirades mémorables de l’État en matière d’informatique et dont ces colonnes font la recension régulière, et peut remonter au remplacement, déjà chaotique, d’un outil logiciel des années 90, le LRP, qui fonctionnait avec une relative satisfaction de ses utilisateurs mais, malheureusement sur un système d’exploitation plus que vieillissant (MS-DOS).
En 2010, LRPPN est donc déployé dans le but de le remplacer. Sans même évoquer les ratages que furent, en parallèle et dans les mêmes domaines, les logiciels ARDOISE et CASSIOPEE, force est de constater que c’est un douloureux échec : plantages, lenteurs, difficile adaptation par rustines multiples aux changements constants de procédure pénale, l’informatique pénale tourne au cauchemar pour la police.
En 2016, il est donc décidé de lancer un nouveau projet, Scribe, dont CapGemini remportera l’appel d’offre. Cependant, après 13 millions d’euros (sur les 8 prévus au départ) et neuf années de bricolages frénétiques, le constat est sans appel : c’est un fiasco. Le souci étant que le logiciel LRPPN, toujours en usage, n’est plus apte à faire son travail et entraîne une multiplication des vices de procédures dont profitent directement les prévenus…
En somme, le président d’un pays incapable de doter ses administrations des outils informatiques essentiels se croit capable de lancer sa bureaucratie sur l’intelligence artificielle avec cet aplomb que seuls les cuistres peuvent déployer en braillant, l’air bravache, « l’intendance suivra ! » avant de trotter, sabre au clair, au milieu d’un champ de betteraves.

Heureusement et pendant ce temps, les entreprises privées du reste du monde n’attendent pas les gesticulations du président français, virilement parti de son côté pour faire avancer les IA « frugales et respectueuses de l’environnement dans une gouvernance mondiale inclusive » et patin-couffin.
Ainsi, outre les modèles de moteur d’IA les plus avancés (Grok 3, GPT 4.5, Gemini 2.0, …) dont les dernières versions sont maintenant disponibles et qui dépassent chaque mois les capacités et performances des précédentes versions, l’intelligence artificielle commence à voir ses domaines d’application s’étendre de plus en plus vite.
C’est par exemple le cas dans celui de la modélisation des génomes avec le modèle d’IA Evo-2 : avec ce moteur totalement open-source, l’IA ne se contente plus de décrire la biologie, elle peut la concevoir et créer une vie synthétique à partir de zéro, des génomes complets ou simuler des cellules entières. Evo-2 prédit les effets des mutations sur les protéines et l’ARN, et les aptitudes des organismes à partir de leur génome.
Les potentialités sont stupéfiantes et les dérives possibles évidemment énormes.

Dans le domaine de la santé, l’IA assiste de plus en plus le personnel médical et si on l’utilise déjà pour l’analyse de l’imagerie médicale, son taux de succès étant maintenant meilleur que celui des radiologues, d’autres usages se font jour chaque mois qui passe. Dernièrement, il apparaît que l’analyse des signaux d’électrocardiogramme par l’IA permet d’obtenir une aussi bonne mesure de l’état du myocarde que des procédures jusqu’alors invasives (ici, la pose d’un cathéter sur le muscle cardiaque droit, ou CCD).
On peut aussi citer les avancées de l’IA en cybersécurité, soit du côté offensif (l’IA est utilisée pour attaquer une cible et produire ensuite un rapport circonstancié des points faibles repérés pour que le client puisse mieux se protéger, comme le propose Dreadnode), soit du côté défensif (l’IA est utilisée pour construire, dans le contexte d’une entreprise, l’ensemble des stratégies de protection et les règles à appliquer pour obtenir le niveau de protection désirée), les deux approches pouvant se complémenter.
Bien sûr, il ne s’agit ici que de quelques exemples saillants d’un mouvement d’ensemble plus profond : tous les domaines d’activités sont (ou seront très bientôt) touchés par l’intelligence artificielle et on comprend, dans ce cadre, les frétillements de la classe politique pour feindre d’organiser ce qui leur échappe complètement.
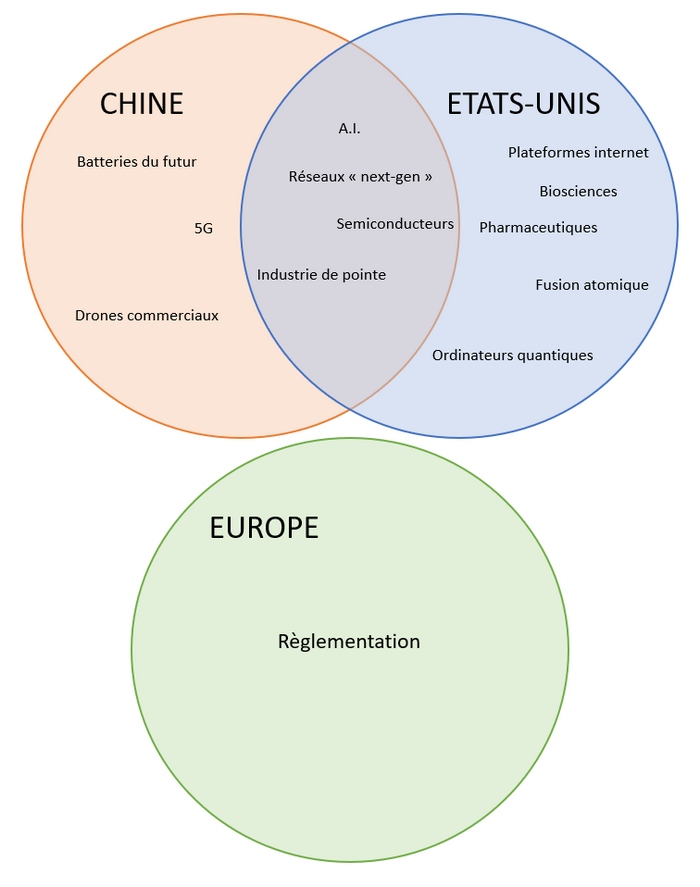
En outre et pour ceux qui en doutaient encore, ces évolutions en matière d’intelligence artificielle marquent le fossé – voire le véritable canyon – qui se creuse entre l’Europe d’un côté, et la Chine et les États-Unis de l’autre. La première a vigoureusement choisi de réglementer et de lancer sa bureaucratie à l’assaut des entreprise qui investissent le domaine, pendant que les seconds déblaient autant de terrain que possible pour qu’elles se développent.
Cependant, à l’instar de l’informatisation de la société qui a permis dans tout l’Occident d’engloutir les gains de productivité ainsi obtenus dans des États providence obèses, on peut à présent redouter que l’Europe et la France choisissent résolument d’utiliser l’intelligence artificielle pour aider le continent à s’accommoder de sa bureaucratie paralysante.
Malgré tout et comme le prouve le projet Scribe, le calibre phénoménal des incapables de compétition qui nous gouvernent actuellement permet de rester optimiste : l’Europe et la France s’effondreront heureusement sous le poids de leur bureaucratie, l’IA n’y pourra rien et c’est tant mieux.